해당 컨텐츠는 진짜 좋은 내용이나 무척이나 긴 내용임을 공지합니다. -_-+ 귀찮으면 읽지 마삼!!
-------------------
1.펜티엄? 펜티엄!
인텔이 P5, P6등의 세대별 이름을 붙인 아키텍쳐 명칭을 사용하다가 펜티엄4를 내놓으면서 발표한 ‘넷버스트’ 아키텍쳐도 발표된지 무려 5년이 지났다. 인텔은 올해 3분기부터 본격적으로 출시될 데스크탑 프로세서, 코드명 ‘컨로(Conroe)’를 시작으로 이제 넷버스트를 보내고 새로운 마이크로아키텍쳐 코어(Core)를 도입한다. 코어는 넷버스트의 한계를 인식하고 이전 펜티엄 3로 회귀하려는 것일까? 아니면 코어는 동네에 새로 이사 온 낯선 무서운 아이일까? 인텔이 코어 아키텍쳐의 핵심으로 부상시키고 있는 와트당 퍼포먼스(Performance per Watt)는 과연 무엇일까?
펜티엄? 펜티엄!
인텔은 넷버스트 아키텍쳐 도입시이전 486 이후 586이라 불렸었던 P5 아키텍쳐의 프로세서부터 사용했던 펜티엄(Pentium)의 이름을 버리고 새 이름을 사용할 것을 고민했었다. 이전 P6 대비 완전히 바뀐 넷버스트 아키텍쳐 이미지를 강화하기 위해서는 펜티엄 브랜드를 유지하기 보다는 무엇인가 새로운 이름이 필요했다는 것이다. 하지만 인텔은 결국 펜티엄4라는 이름으로 결국 펜티엄 브랜드를 지속하게 되는데, 이는 컴퓨터용 프로세서로써 펜티엄의 인지도가 그만큼 막강했다는 것도 한 가지 이유지만 인텔 프로세서 아키텍쳐가 세대를 거듭하면서도 결국 이전 펜티엄 프로세서(P6)의 장점을 계승하면서 성능 도약을 위한 새로운 부분이 추가되었다는 특징도 고스란히 넷버스트에서 승계되었기 때문이다.
펜티엄(Pentium)이란 이름 자체는 5세대(Pent-) 프로세서란 이름을 강조하기 위해서 만들어진 것이다. 사실 286, 386, 486이란 이름으로 대변되던 프로세서 세대를 펜티엄이라는, 다소 직관적이지 못한 이름으로 바꾼 것에는 AMD, 사이릭스등의 x86 프로세서 경쟁 업체들이 586, 686 시리즈등으로 이 이름을 그대로 프로세서에 적용하기 시작하면서 이를 피하기 위해 사용한 것인데, 이후 P6 아키텍쳐에서는 그러면 섹시움(Sexium)을 사용할 것이냐는 장난기 어린 비판도 있었지만 결국 인텔은 P5 이후에 P6, 그리고 넷버스트를 거치면서 10년이 넘는 기간 동안 펜티엄 브랜드를 유지해 왔다.
<펜티엄의 변천사>
인텔은 현재 출시되는 넷버스트 아키텍쳐의 듀얼 코어 프로세서(프레슬러)에도 펜티엄 브랜드를 사용하고 있으며 모바일 부분에서 펜티엄4M과는 다른, 배니어스(Banias) 코어의 프로세서에도 펜티엄M 브랜드를 여전히 사용하고 있다. 그러나 코드명 요나의 배니어스 기반 모바일 듀얼 코어 프로세서에는 펜티엄 브랜드를 드디어 떠나서 코어 듀오(Core Duo) 프로세서를 사용했으며 이제 본격적으로 언급하기 될 코어 아키텍쳐의 프로세서에서도 마침내 펜티엄 이름을 버리고 ‘코어’라는 이름을 프로세서 공식 브랜드명으로 사용하게 된다.
10년을 넘게 유지해온 펜티엄을 버리고 새 이름을 사용한다는 것은 그만큼 인텔이 코어 마이크로아키텍쳐에서 많은 혁신을 이루어내었고 인텔이 이 프로세서가 전세대와 밑바탕부터 다르다는 것을 보여주는 것이기도 하지만 여전히 코어 아키텍쳐는 P5, P6, 넷버스트, 배니어스 아키텍쳐의 진화를 거치는 동안 각 세대의 장점을 융합시킨 새롭지 않지만 새로운 아키텍쳐로 보는 것이 옳다.
2.코어式 철학 : 무어의 법칙은 건재하다
“더 높은 성능을 구현하기 위해서 더 높은 전력을 소모할 필요는 없다“
이는 인텔이 지난 개발자 포럼에서 코어 아키텍쳐를 위와 같은 발언으로 소개했다.
인텔의 새로운 마이크로아키텍쳐에 대한 고민은 특정 부분이 아니라 데스크탑, 모바일, 서버 전 분야에 대한 고민에서 출발한 것이다. 데스크탑 부분에서 인텔은 높은 파이프라인 단계(31 단계)의 넷버스트 아키텍쳐 펜티엄4로 클럭을 끌어올리며 성능을 높이는데 성공했다. 그러나 클럭 속도를 끌어올릴 수록 높은 전력소모량과 발열도 같이 증가, 결국 이러한 방법으로 성능 향상은 한계에 도달했다. 펜티엄4는 0.25>0.18>0.13>0.09 미크론으로 제조 공정의 미세화에도 불구하고 결국 전력 소모량을 낮추지는 못했다. 클럭 경쟁을 종료한 인텔은 결국 멀티 코어와 캐쉬 크기를 끌어올리는 방법을 선택하게 되는데, 여전히 현 넷버스트 아키텍쳐에서는 클럭을 낮추더라도 코어수를 늘리고 캐쉬를 늘리는 만큼 전력 소모량이 그대로 증가했기 때문에 본격적인 멀티 코어 시대에 맞는 아키텍쳐가 절실히 필요하게 된 것이다.
모바일 부분에서는 넷버스트의 이런 구조 때문에 펜티엄4M 이라는 모바일용 데스크탑 프로세서를 내놓고도 또 다른 아키텍쳐의 펜티엄M까지 내놓게 된다. 노트북의 특성상 배터리 수명이 성능 이상으로 중요한 인자이며 휴대성을 강화한 슬림형 노트북의 경우 작은 크기의 냉각 솔루션 역시 필요했기 때문이다. 또한 24시간 무결성 동작이 필요하고 블레이드 서버와 같이 높은 설치 밀도를 요구하게 된 서버 환경에서도 마찬가지이다.
결국 인텔은 데스크탑과 서버 부분에서는 넷버스트 아키텍쳐의 프로세서, 그리고 모바일 프로세서에서는 펜티엄M의 배니어스 코어 아키텍쳐로 2개의 아키텍쳐 라인을 동시에 운용하게 되는데 코어 아키텍쳐의 등장은 그동안 분리되었던 각 분야에서 아키텍쳐를 통합하는 것과 동시에 앞으로 성능향상의 주요 지침이 될 멀티 코어 프로세서 전략에 있어 핵심이 된다.
코어 아키텍쳐는 인텔 이스라엘팀이 개발한 것으로 이 팀은 현재 펜티엄M 프로세서의 아키텍쳐를 개발한 팀으로 알려져 있다. 코어가 발표되면서 가장 논쟁거리가 되었던 것은 과연 이것이 “넷버스트를 포기한 인텔이 펜티엄 3로 회귀”하였냐는 것인데 코어 자체적으로는 P6 아키텍쳐에 기반을 둔 배니어스부터 출발했지만 펜티엄3로 회귀로는 보기 어렵고 그렇다고 펜티엄3에다가 단순히 넷버스트에서 배운 것을 몇 개 적용했다고 보기에도 어렵다. 코어는 위 언급한 아키텍쳐들의 장점을 가지고 왔지만 백지에서 출발해서 설계한 완전히 새로운 차세대 아키텍쳐로 보아야 한다.
물론 뒤의 코어 아키텍쳐에 대한 설명에는 P6 , 그리고 넷버스트와의 비교를 통해서 차이점을 위주로 언급하게 될 것이지만, 이것은 코어가 이 아키텍쳐들에서 시작했다기 보다는, 인텔의 진화 선상에서 이전 세대의 아키텍쳐와의 관계를 설명하기 위한 것으로 보는 것이 옳다.
멀티 코어가 프로세서 업계에서 대세가 되면서 x86 프로세서이외에도 RISC 프로세서, 그리고 여타 아키텍쳐의 프로세서들도 모두 멀티 코어로 진화하고 있다. 그러나 인텔의 멀티 코어 전략은 여타 업체와는 많은 차이점을 보인다.
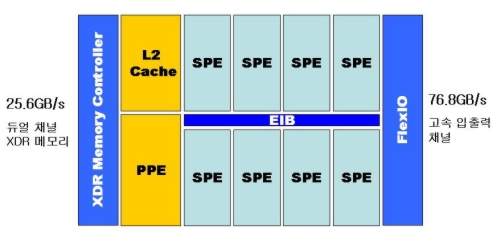
현재 8개의 코어를 장착한 썬 마이크로시스템즈의 나이아가라(T1)이나 IBM, 소니, 도시바의 합작인 셀 프로세서의 경우 멀티쓰레드, 즉 다수의 쓰레드를 동시에 처리하도록 하는 연산의 병렬화, 즉 코어수를 늘림으로써 병렬연산 기능 강화에 치중한 대신, 싱글 쓰레드 성능은 어느 정도 포기한 구조를 택하고 있다. 이는 멀티 코어 프로세서를 구성하는 각 코어에 수퍼스케일러 프로세서의 대표적인 특징인 비순차적 실행(Out Of Order Execution)을 없앤 특징(즉 반대로 초기 프로세서의 특징인 순차적(In-Order Execution) 실행 구조를 택하고 있다)에서 잘 드러난다. 즉 각 코어구조를 최대한 단순화 시키고 여러 개의 코어 구동을 통해서 연산 병렬화에 주력하겠다는 것.
<셀 프로세서의 기본구조. 간단한 구조의 SPE로 구성되어 있다>
인텔의 코어 아키텍쳐는 이 부분에서 여타 업체의 ‘멀티 코어’전략과는 확연히 다른 모습을 보여주며 오히려 비순차적 실행 범위를 더 넓히고 하나 코어 자체의 성능을 높이는 방향으로 설계되었다. 코어 아키텍쳐는 기존 싱글 쓰레드 기반의 프로세서의 특징, 비순차적 실행 유닛을 그대로 고수하면서도 이를 개선시켜, 각 코어에서 성능을 양보하지 않겠다는 의지가 반영된 것이다. .
즉 이와 같은 접근 구조는 결국, 앞으로 멀티쓰레드 성능이 보장된 애플리케이션에서 높은 성능을 내도록 한 것 이외에도 현재 주류를 이루고 있는 싱글 쓰레드 애플리케이션에서도 탁월한 성능을 낼 수 있도록 한 것이다. 성능에 대해서는 이후에 언급하겠지만 현재 주류를 이루는 싱글 쓰레드 애플리케이션, 특히 게임등에서 컨로가 높은 성능을 낼 수 있는 이유가 여기에 있다. 이러한 이유로 코어 아키텍쳐의 각 코어는 비순차적 실행에 필요한 연산 유닛과 회로를 줄여 다이 크기를 줄이기 보다는 이 특성을 고스란히 유지하면서도 전력 효율이 높도록 구조를 갖추는 방향으로 설계되었다.
그렇다면 펜티엄4와의 넷버스트와 기본적인 차이점은 무엇인가? 넷버스트는 깊은 파이프라인 구조로 클럭 속도를 끌어올리는 것으로 성능향상을 도모할 수 있게 되었지만 코어 아키텍쳐는 칩에 코어수를 늘리는 것으로 성능향상을 도모할 수 있도록 설계되었다. 매 약 18개월마다 트랜지스터 집적수가 2배, 그에 따라서 성능 향상도 이루어진다는 매우 ‘무어의 법칙’스러운 설계이다.
3.코어, 그 뿌리를 찾아서
인텔은 코어 아키텍쳐를 백지상태에서 완전히 설계를 다시 한 것이라고 밝혔다. 외형상으로 현재 출시되는 넷버스트 아키텍쳐와 그리고 배니어스, 펜티엄III 아키텍쳐(P6) 와 비교하자면 단연코 펜티엄III와 더 근접한 모습을 취하고 있다는 것을 알 수 있다. 사실상 인텔이 넷버스트 아키텍쳐의 펜티엄4를 출시할 때 내새웠던 기능들은 이번 코어 아키텍쳐에서는 찾기가 어렵다.
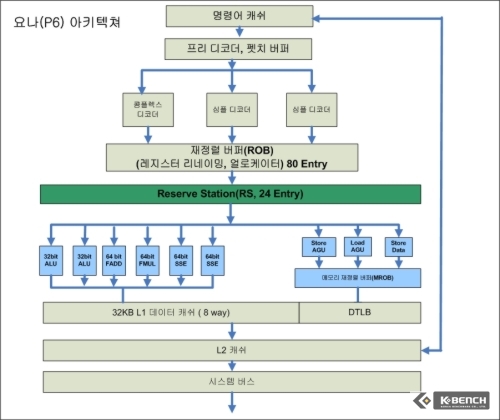
한 인텔 관계자에 의하면 코어 아키텍쳐 설계시에 이전 펜티엄4에서 가져온 것은 프리펫칭(Pre-Fetching)과 관련된 부분이 전부였고 실질적으로 밑바탕이 된 것은 현재 코어 듀오란 이름으로 출시되는 요나(Yonah) 프로세서였다고 한다. 현재의 버스 구조, 그리고 몇몇 알고리듬부분을 제외하고는 펜티엄4와 공통점을 찾을 수 없고 펜티엄III를 기반으로 한 요나의 후예이기에 코어 아키텍쳐는 펜티엄III와 많은 부분에서 공통점을 피할 수 없다.
이렇게 때문에 코어 아키텍쳐는 P6(펜티엄 프로~ 펜티엄 III)의 후예인 P8로 불리기도 한다. (물론 인텔은 이렇게 부르기를 거부하겠지만). P6의 후속버전, 즉 P7격은 현재 펜티엄 M인 배니어스와 요나(사실 요나 프로세서의 아키텍쳐는 인텔이 정식 명칭을 부여한 바 없다)이고 ,그리고 이의 후속 버전으로 코어 아키텍쳐가 P8이 된다는 것.
일단 펜티엄4의 근간을 이루었던 넷버스트 아키텍쳐와 코어 아키텍쳐, 그리고 P6 아키텍쳐의 간추린 다이어그램을 보면서 근본적인 차이를 이해하도록 하자.
4.디코딩 유닛 : 변화의 바람
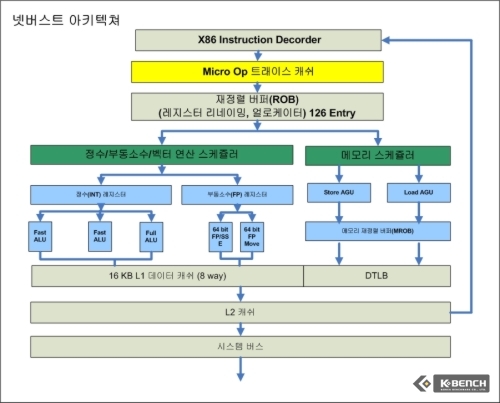
넷버스트가 이전 P6 아키텍쳐에서 가장 많은 차이점으로 부각했던 것은 바로 매우 많은 단계의 파이프라인, 즉 클럭 속도를 끌어올릴 수 있다는 것이었다. 그러나 시스템 전체 측면에서 프로세서 클럭을 높에 끌어올릴 수 있다는 것이 전체적인 성능향상을 의미하지는 않는다. 현재 펜티엄 프로세서의 최고 클럭은 3.8GHz이며 반면 메인 메모리의 클럭 속도는 667MHz에 지나지 않는다. 더 정확히 하자면 내부 데이터 버스의 폭과 어드레싱 능력, 그리고 대역폭을 비교해야 겠지만, 일단 프로세서 클럭을 끌어올리는 것, 그리고 깊은 단계의 파이프라인은 결국 이를 받쳐주는 메모리 기술과 데이터 수집/캐쉬/재정렬 기술이 없으면 실질적인 성향 향상을 도모하기는 어렵다.
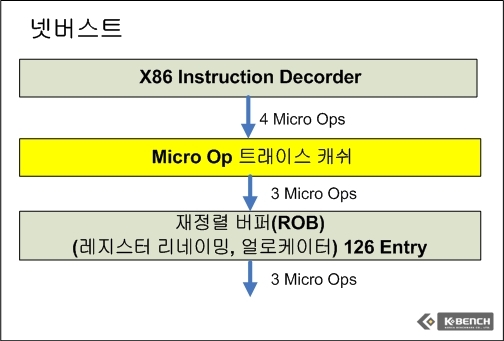
때문에 인텔은 넷버스트의 주요 기능으로 트레이스 캐쉬(Trace Cache)를 도입했다. 트레이스 캐쉬는 Micro-Op (프로세서 연산 유닛에서 처리하기 위해 명령(Instruction)을 단순 연산자, 일례로 덧셈이나 곱셈으로 쪼갠(Decoding) 것을 의미하며 이러한 x86의 특징으로 인해서 RISC와 CISC의 경계가 모호해졌다고 해도 무방하다)을 캐쉬에 담아놓고 프로세서 연산 유닛이 이를 필요로 할 경우 명령어를 불러서 다시 디코더를 통해서 나온것을 기다리지않고 바로 디코딩된 Micro-Op을 가져올 수 있도록 저장해놓은 캐쉬 공간이다.
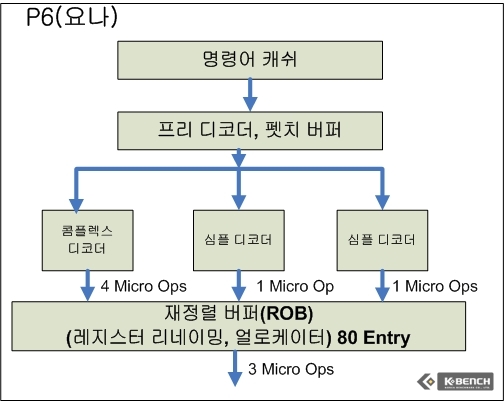
트래이스 캐쉬의 도입으로 인해서 인텔은 트레이스 캐쉬 이전 단계에 거대한 디코더 유닛을 넷버스트에서 필요로 했다. 그리나 이전 요나의 경우 디코더를 심플 디코더 2개, 콤플렉스 디코더 1개 (심플 디코더의 경우 1개의 Micro Op으로 변환할 수 있는 명령어(Instruction)을 변환하며 콤플렉스의 경우 1개의 명령어가 1-4개의 Micro Op들로 변환되는 명령어에 대한 디코딩을 진행한다)를 갖추고 있으며 트래이스 캐쉬 같은 별도의 보조 캐쉬없이 바로 재정렬 버퍼(Redorder Buffer) 공간을 통해서 연산 유닛으로 데이터가 공급되게 된다.
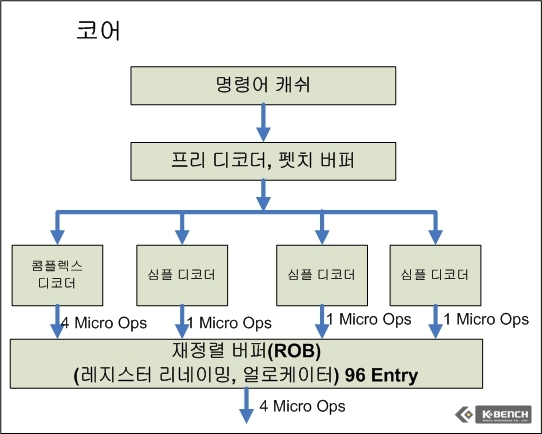
그러나 코어 아키텍쳐의 경우에는 넷버스트 대비 상대적으로 파이프라인 단계가 14단계로 짧다(아직 각 파이프라인 각각 단계에 대한 자세한 정보는 인텔이 공개하지 않았다). 파이프라인 개수가 줄어든 것도 한 가지 이유이고, 진보된 캐쉬 기술을 도입한 것도 이유이겠지만 일단 넷버스트가 자랑스럽게 내밀었던 하이퍼파이프라인(높은 단계의 파이프라인)과 트레이스 캐쉬는 코어 아키텍쳐에서는 자취를 감추었다. 대신 P6에서 사용했던 디코더 수를 늘렸으며 심플 디코더가 3개, 1개의 컴플렉스 디코더를 갖추고 있다. 이외에 바로 중간 캐쉬(트래이스 캐쉬) 없이 연산 유닛으로 공급되는 구조를 갖춘 것은 P6와 유사하다.
5.똑똑 해진 디코딩 : 매크로/마이크로 퓨전
매크로 Op 퓨전(Macro Ops Fusion)
그렇다고 해서 코어의 디코더 부분이 P6에서 단순히 디코더 수를 늘린 것은 아니다.
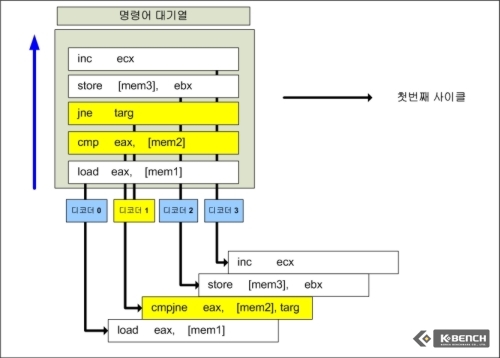
코어 아키텍쳐는 각 명령어가 Micro-Op으로 디코딩 되기 전에 몇몇 특정 종류의 명령어를 묶어서 하나의 Micro-Op으로 만드는 기능을 구비하고 있다. 매크로 퓨전(Macro Fusion)이라는 이름의 이 기능은 비교 명령인 cmp(Compare)와 조건 분기 명령인 Jne(Jump if Not Equal)을 하나의 Micro-Op으로 만들어 연산 유닛에 보낸다. 즉 매크로 퓨전 없이는 각기 명령어마다 1개의 디코딩 과정을 거지고 또 각기 연산 유닛에 보내졌던 것을 하나의 Micro-Op, 위의 예에서는 cmpjne,으로 만들어 연산 유닛에 보내게 됨으로써 디코딩 유닛에서 전체적으로 디코딩 해야 할 명령어 수가 줄어들고, 결과적으로는 더 많은 명령어를 (같은 사이클 내에) 디코딩할 수 있다는 것을 의미한다. 즉 코어가 가진 4개의 디코더(1개 콤플렉스, 3개 심플)에서 한 사이클에 4개의 명령어 디코딩이 가능한 것을 매크로 퓨전으로 최대 5개까지 한 사이클에 할 수 있다는 것이다.
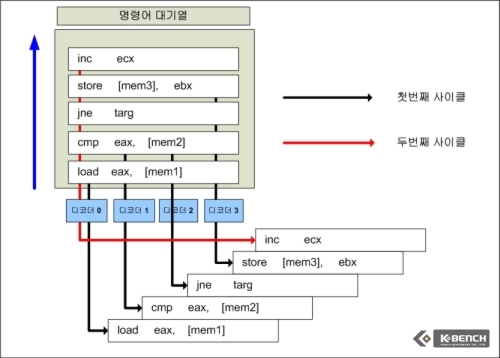
이 예제는 일반적인 x96 명령어가 디코딩 되는 과정을 그린 것이다.
만약 디코더 유닛이 4개가 붙어 있다면 아래서부터 차례로 대기열에 대기중인 명령어들이 4개가 디코딩 되고 5번째 명령어는 다시 “디코더 0”에서 2번째 사이클에서 디코딩 된다.
그러나 매크로 퓨전이 적용된 코어 아키텍쳐는 cmp와 jne를 하나의 Micro Op으로 디코딩 가능, 결국 해당 예제에서 1사이클만에 명령어 5개를 디코딩할 수 있다는 것을 보여주는 것이다.
인텔에서는 x86 명령어(Instruction)-즉 디코더에서 이보다 작은 단위의 연산인 Micro Op으로 쪼개기 전까지 명칭-를 Macro Op이라고 부르는 것으로 보인다. 실질적으로 매크로 퓨전이 궁극적으로 의미하는 바는 각기 다른 Micro Op으로 쪼개질 명령어(Instruction, 즉 Macro-Op)을 하나의 Micro Op으로 디코딩을 할 수 있다는 의미이다.
그렇다면 실질적으로 컴퓨터를 사용시에 프로세서에서 이 매크로 퓨전으로 실질적인 성능 향상은 어느 정도 될까? 이는 전적으로 혼합, 즉 퓨전의 대상이 되는 cmp, jne의 사용빈도에 달려 있는데 애플리케이션 구동시 전체 총 디코딩되는 Micro-Op의 전체 수를 약 15%선까지 줄일 수 있다고 한다.
이는 단순히 디코딩 되는 명령을 줄여 성능을 끌어올리는 이점만을 제공하는 것은 아니다. 디코더가 처리해야할 명령의 수가 준다는 것은 바로 전력 소모량을 낮출 수 있다는 결과 역시 가져온다.
마이크로 Op(Micro-Op) 퓨젼
위의 매크로 퓨전이 명령어의 2개의 명령어를(코어 아키텍쳐의 경우 Cmp와 Jne가 되겠다) 하나의 Micro-Op으로 디코딩할 수 있는 명령어(cmpjne)로 만드는 과정을 거치는 것이라면 마이크로 퓨전은 이미 인텔이 요나에서 선보였던 것으로 이미 명령어(Instruction)에서 디코더를 지나 Micro Op으로 쪼개진 상태에서 하나로 묶을 수 있는 Micro Op들의 쌍을 찾아서 묶어서 연산 유닛으로 보낸다는 것을 의미한다. 이 기술도 근본적으로 처리할 Micro-Op의 수를 줄여줌으로써 성능 향상과 동시에 전력 소모량 절감의 효과를 가져온다. 인텔은 마이크로 퓨전으로 전체 파이프라인에서 처리해야할 Micro Op의 수를 약 10% 정도 절감할 수 있다고 밝힌 바 있다.
한편 이러한 Micro-Op 절약하기 테크닉만이 코어 아키텍쳐의 디코딩 유닛에서 유일한 장점은 아니다. 넷버스트 아키텍쳐의 경우 1개의 대형 디코딩 유닛을 갖추고 있지만 (이 자체가 하나의 거대한 콤플렉스 디코더로 봐야 한다) 사이클당 3개의 Micro Op 만을 트레이스캐쉬를 거친 히후에 연산 유닛으로 보낼 수 있다. 그러나 코어의 경우 총 4개( 3개 심플 + 1개 콤플렉스)로 사이클당 7개의 Micro Op을 연산유닛으로 보낼 수 있다.
6.와이드 와이드 와이드 : 무엇이 넓어졌나?
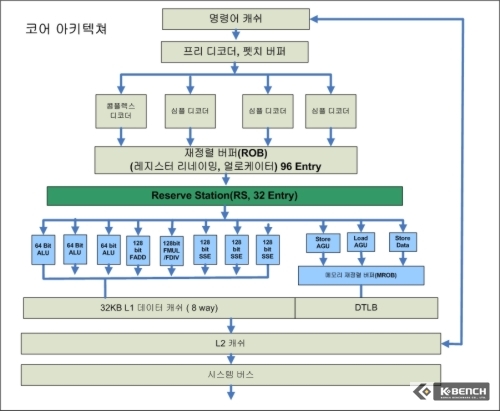
코어 아키텍쳐는 기본적으로 이전 세대의 프로세서 대비 실행 유닛과 스케쥴링 부분에 있어 이전 세대의 프로세서를 압도한다. 여기에는 각 연산 단계(파이프라인)에서 더 많은 디코딩 로직, 더 많은 재정렬 버퍼 공간, 더 큰 명령어 대기소(Reservation Station), 그리고 더 많은 포트를 가지고 있다는 것을 의미한다.
사실 연산(Execution) 유닛에 해당 Micro-Op을 모든 연산 유닛에 지속적으로 보급을 위한 비순차적 실행 부분은 넷버스트와 코어 아키텍쳐와 직접적인 비교가 불가능하며 바로 이것이 코어 아키텍쳐가 왜 넷버스트가 아닌 P6의 후손에 가깝다는 평을 듣는 이유이다.
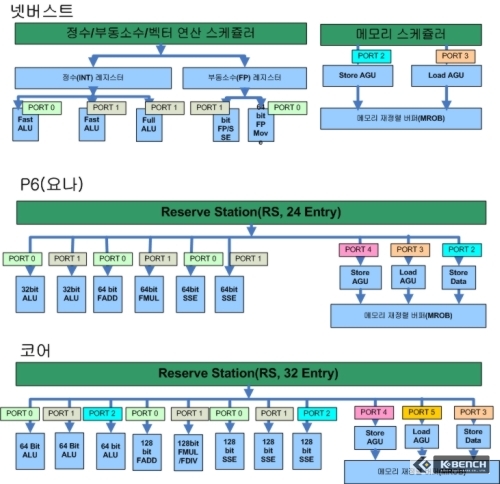
코어 아키텍쳐는 P6에서와 같이 통합적인 보관 장소(RS, Reserve Station)을 통해서 최종적으로 연산 유닛에 명령어/데이터를 공급하게 되지만 넷버스트는 이와 달리 정수, 소수 연산과 벡터유닛(SSE), 그리고 메모리에 대해서 각각 독립적인 분배형 (Distributed) 스케쥴러를 가지고 있기 때문이다. 직접적인 비교는 불가능하나 코어의 경우 RS 엔트리(분해된 Micro Op의 연산 유닛으로 재정렬을 위한 공간)가 32개, 요나의 경우 24개이고 분배형 스케쥴러를 사용하는 넷버스트의 경우 46개(연산 유닛 38개, 8개 메모리)를 사용하고 있다. 엔트리만 보자면 넷버스트에 비해서 코어가 작아 보이지만, 결국 파이프라인 단계가 현저하게 낮아서 스케쥴링에 넷버스트같이 많은 공간이 오히려 코어에서는 필요하지 않아 보인다.
일단 이 스케쥴러, 혹은 RS를 기준으로 디코딩되고 난 Micro Op의 연산 유닛까지의 흐름을 따라가보자.
펜티엄4 넷버스트의 경우 디코딩 되고 이후에 트래이스 캐쉬에 저장된 Micro Op은 사이클당 3개를 재정렬 버퍼(Reorder Buffer, ROB)로 보낼 수 있으며 여기서 연산 유닛(벡터(SSE/SMID), 스칼라(정수, 부동소수), 메모리(로드-스토어)의 3종으로 보통 구분된다)의 데이터/명령어 공급을 위한 스케쥴러 및 메모리 스케쥴러로 사이클당 3개의 Micro Op의 속도로 전송하게 된다.
요나(코어 듀오)의 경우에는 위에서 언급했듯이 디코딩 유닛(심플 디코딩 유닛)의 개수가 코어 보다 하나 작으며 사이클당 최대 6개의 Micro Op을 디코딩 해서 ROB로 보내고 최종적으로 RS에서도 연산 유닛으로 사이클당 3개의 Micro OP을 RS에서 연산 유닛으로 보낼 수 있다.
즉 시동이 걸려 있고 달릴 준비를 하는 연산 유닛 입장에서 보자면 들어오는 연산 데이터/명령어의 공급 속도는 같이 사이클당 3개의 Micro Op이다. 그러나 위에 언급했듯이 요나의 경우에는 Micro Op Fusion을 지원하기 때문에 마이크로 퓨전의 효용성에 따라서 실제 각 연산 유닛의 효용성을 떠나 전체 프로세서 생태계에서 처리하는 명령어의 수는 요나가 훨신 많을 것으로 추정된다.
코어 아키텍쳐는 요나보다도 1개 더 많은 심플 디코더를 가지고 있어 사이클당 최대 7개의 Micro Op을 디코딩 할 수 있고 이후에 ROB, RS그리고 연산 유닛까지도 사이클당 4개의 Micro Op을 전송시킬 수 있다. 이는 단순히 요나에 대비해서도 33% 더 많은 것인데, 비록 사이클당 1개의 차이라고 해도 엄청난 클럭 속도에서 데이터/명령어의 이동을 생각한다면 작은 차이라고 볼수 없을 것이다. 여기에 위에 매크로 퓨전, 마이크로 퓨전까지의 혜택을 더한다면 상대적으로 넷버스트의 펜티엄 4 프로세서 대비, 낮은 클럭이라도 실제로 연산 유닛으로 데이터/명령어를 재정렬하고 공급하는 처리량은 단순 33% 수치 이상일 것으로 관측된다.
이것을 인텔은 “와이드 다이내믹 익스큐션(Wide Dynamic Execution)”이라 칭한다.
7.진정한 128비트 SSE 구현
그렇다면 RS, 그리고 스케쥴러를 지나 이제 연산 유닛을 비교해보자.
코어 아키텍쳐의 경우 RS를 지나 본격적으로 벡터(Vector ALU), 스칼라(Scalar ALU), 그리고 메모리 연산(Store와 Load를 실행) 유닛으로 접속하는 포트를 6개를 제공한다. 코어를 있게 한 P6의 경우(펜티엄3)의 경우에는 5개의 포트를 제공하고 있으며 넷버스트의 경우에는 4개를 가지고 있다.
코어의 경우 포트 수가 액면상 늘어난 것을 제외하더라도 일단 가장 눈에 띄는 것은 연산 유닛으로 에 할당된 포트 수가 3개라는 것이다. P6의 경우에는 2개가 할당되었었으며 넷버스트의 경우에도 2개만이 ALU에 할당되었고 나머지는 메모리 연산 부분으로 할당되었었다. 코어의 경우에는 3개의 포트로 인해서 사이클당 3개의 연산을 지속적으로 처리가 가능하다.
애초에 펜티엄 프로로 시작하고 이후에 펜티엄 III로 진화하면서 벡터 연산 유닛, 즉 MMX와 SSE를 연산 유닛 부분에 추가하면서 문제는 RS에서 ALU로 오는 포트수가 작아서 이 부분에서 병목 현상이 발생할 수 있다는 것이었다. (특히 2 사이클을 필요로 하는 SSE 명령어의 처리 경우에는 포트의 대역폭이 부족했을 것이다.) 이 문제는 여전히 ALU에 2개 포트만을 가지고 있는 넷버스트에서도 잔존했다. 넷버스트의 ALU(Fast ALU 유닛)는 다른 부분에 비해서 2배속도의 클럭으로 동작한다. 즉 이론상으로는 클럭당 처리할 수 있는 최대 명령어는 넷버스트에서는 4개이다. 그러나 4개가 되어야할 경우에는 반드시 이 ALU에서 처리할 수 있는 단순(Simple) 연산일 경우에만 클럭 사이클당 4개를 처리할 수 있다. 즉 지속적으로 처리가 가능하다는 면에서는 코어가 더 균형잡힌 구조를 가지고 있다.
코어의 연산 유닛중 가장 뛰어난 부분은 바로 SSE 유닛이다. 인텔의 SSE(Streaming SIMD Extension)는 128비트 벡터의 지원이라는 것으로 호평을 듣기도 했지만 반면 P6 코어, 그리고 최근의 넷버스트까지도 64비트의 내부 데이터경로로 인해서 완전하지 못하다는 평을 들어야 했다. 코어의 3개의 SSE 유닛은 128 비트로 동작한다. 즉 128비트의 SSE 명령어를연산하는데 있어 유닛당 당 1개의 클럭 사이클만을 필요로 한다는 것이다. 이와 비교해서 넷버스트의 SSE 유닛은 64비트로 동작하는 것 2개를 가지고 있으며 128비트 연산시에 2개의 클럭 사이클을 필요로 한다. 코어의 전신인 요나도 64비트 SSE 유닛을 가지고 있다.
이와 비교해서 코어는 최대 4개의 배정밀도(DP, Double Precision, 64비트) 부동 소수 연산을 한 사이클에 처리할 수 있다. 인텔은 이를 어드밴스드 디지털 미디어 부스트(Advanced Digital Media Boost)라는 이름으로 코어 아키텍쳐의 핵심 기능으로 내세우고 있다.
이 역시 처리되는 Micro-Op의 단위수를 줄여서 더욱 빠른 성능을 도모함과 동시에 연산 유닛 입장에서는 해당 연산부하에 대해서 전력 소모량을 줄일 수 있는 것이다.
* SSE4
한편 인텔은 이번 코어 아키텍쳐에서 새로운 SSE 명령어를 추가하였으나 이를 적극적으로 홍보하고 있지는 않다. 아직까지 SSE4라고 알려진 이 명령어는 기존 SSE/SSE2/SSE3에 16개의 새로운 명령어가 추가된 것이며 필자의 질문에 인텔 엔지니어는 이것이 꼭 필요한 사람에게만 유용한 것이라고 그다지 부각되는 기능은 아니라는 식으로만 답했다. 이 명령어들은 원래 4GHz의 장벽을 넘을 기대주였지만 좌초된 테자스(Tejas)에서 적용할 예정이었던 것으로 추정된다.
이에 대한 구체적인 내용은 코어2 듀오가 정식 발표되는 시점에서 인텔이 공개할 것으로 전망된다. SSE4 명령어에 대한 추측 사항이 이미 인터넷을 통해서 공개된 바 있는데 이것은 어디까지나 추측이고 정확한 것은 아니다. 관심있는 사람은 방문해보기 바란다(일본어)
펜티엄 프로 이후로 인텔은 명령어를 가져오고 실행하는데 있어 비순차적(Out Of Order) 실행을 도입했다. 메모리 재정렬 버퍼-MROB(Memory Reorder Buffer)에서도 비순차적 실행을 위한 명령어/데이터 재정렬시에 인텔은 이 부분에서도 캐쉬 메모리, 혹은 메인 메모리에서 찾는 데이터를 가져오는데 필요한 레이턴시를 줄일 수 있는 방법을 찾아냈는데 이것을 메모리 디스앰비규에이션(Memory Disambiguation) 이라 지칭하고 있다.
일반적으로 메모리 그리고 캐쉬에서 데이터를 가져오고 저장하는 메모리 연산 유닛 기능은 가장 간단하게 Load(불러오기)와 Store(저장하기)로 정의된다. 비순차적 실행을 위한 재정렬에 있어 프로세서 입장에서 이 Load와 Store의 순서를 정하는 것은 매우 중요하다. 만약 한 데이터를 특정 저장소(캐쉬, 메모리 혹은 레지스터 파일)에서 저장(Store)해서 다시 불러오기(Load)를 시행하는 연산 과정이 있다고 가정하면, 이 시행 순서를 바꿀수가 없다. 만약 먼저 Load를 같은 장소에서 불러오고 다서 Store를 한다면 결국 데이터는 원하는 값대로 갱신되는 것이 아니기 때문이다. 데이터 저장소 입장에서 남아 있는 데이터 값의 입장에서 보면 이해하기 쉽다. 즉 Load를 시행하기 위해서는 Store가 진행되는 동안 기다려야 한다.
위와 같은 이유로 인해서 비록 비순차적 실행을 도입했더라도 인텔은 넷버스트 아키텍쳐의 펜티엄4까지 반드시 Store와 Load에서 같은 메모리 주소를 참조하고 있는지 반드시 확인하도록 했다. 만약 섞인 메모리 명령어 중에서 Store가 저장 메모리 장소가 정확하지 않을 경우 이를 Load 이전에 실행하는 것을 엄격하게 막았다. 즉 만약 Store의 주소가 명확해지고 나서 Load와 같은 메모리 장소를 사용한다는 것이 알려지게 되면 결국 잘못된 연산 결과를 낼 수 있었기 때문이다.
문제는 이와 같은 Load, Store간의 관계에서 실질적으로 같은 메모리 장소를 사용하고 반드시 순차적으로 실행되어야 하는 것 (이것을 Memory Alias라고 인텔은 부른다)이 실질적으로 ROB에서 시행되는 전체 명령어 중에서 단 3% 정도 밖에 되지 않았다는 것. 나머지 97%는 같은 주소를 참조하지 않는 False Aliasing이었다고.
이 경우에는 Load, Store의 순서를 변경할 수 있다. 위에서 언급했듯이 메모리 디스앰비규에이션은 데이터를 불러오고 저장하는데 있어 레이턴시를 줄이는 것이 목표라고 했다. 그렇다면 이 순서를 바꾸는 것으로 어떻게 레이턴시를 줄일 수 있을까? 아래 그림을 참조하도록 하자.
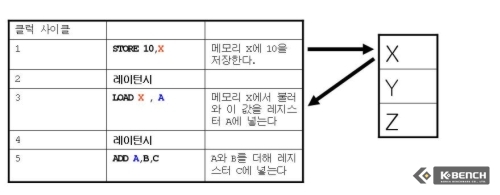
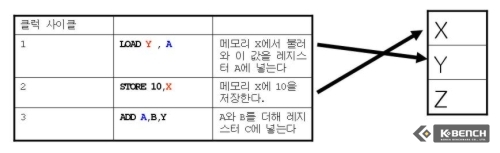
먼저 STORE와 LOAD가 같은 메모리 값을 참조하는 경우를 보자. 이 경우 X에 먼저 10이란 값을 저장한다. 그렇다면 다음 LOAD는 같은 메모리 장소X에 저장된값을 불러와서 레지스터 A에 저장해야 하기 때문에 STORE가 실행되는 1클럭 동안 전까지 기다려야 한다. 이는 STORE가 완료되고 LOAD를 시행하기 이전에 1 클럭의 레이턴시가 발생한다는 것을 의미한다. 이후에 A, B 레지스터에 적힌 값을 더해서 레지스터 Y에 저장하게 되는 과정에서도 역시 X에서 값을 불러와서 A에 넣기 위해서 1클럭을 소요하고 이는 이만큼 기다려야 한다는 것을 의미한다. 이 경우에는 STORE, LOAD의 순서를 바꿀수 없으며 이것이 바로 위에서 언급한 Memory Alias이다.
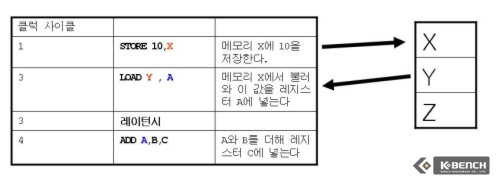
그러나 만약 STORE와 LOAD가 같은 메모리 값을 참조하지 않는다면 어떻게 될까?(이 경우를 False Aliasing이라고 한다) 그림에서 2번째 경우를 보면 STORE의 경우 메모리 X를 참조하고 LOAD의 경우 메모리 Y를 참조한다. 이 경우 LOAD가 STORE가 완료될때까지 기다릴 필요가 없기 때문에 레이턴시가 발생하지 않는다. 그러나 여전히 ADD에서 필요한 값을 구하기 위해서는 LOAD가 완료될 때까지 기다려야 한다. 이것이 현제 넷버스트까지 할 수 있던 최선의 방법이었다.
그러나 만약 같은 메모리를 참조하지 않는다면 이 과정에서는 아예 레이턴시를 없애 버릴 수도 있는데 이는 실행 순서를 바꿈으로써 가능하게 된다. 메모리 디스앰비규에이션이 적용될 경우 STORE와 같은 메모리 참조값을 사용하지 않는 LOAD를 STORE보다 실행한다. 이로 인해서 뒤에 ADD 연산은 물론 LOAD가 완료될때까지 기다려야 하지만 이 기다리는 시간을 허비 하지 않고 바로 STORE 작업을 시행할 수 있으며 낭비되는 레이턴시를 없앨 수 있다.
인텔은 메모리 디스앰비규에이션, 즉 LOAD와 STORE의 순서를 바꾸어 레이턴시를 낮추는 것만으로도 최고 40%의 성능향상이 있다고 밝혔다.
9.캐쉬, 마침내 분단의 벽을 허물다
앞서서 위에 언급한 내용들은 모두 코어 아키텍쳐의 하나의 코어에 해당되는 기술이다. 코어 아키텍쳐의 프로세서는 기본적으로 듀얼 코어로 구성되어 있으며 이후에 인텔이 보급형 프로세서 시장을 타겟으로 싱글 코어의 코어 아키텍쳐 프로세서도 내놓을 것으로 전망된 바 있지만 기본적으로 코어는 듀얼 코어 프로세서를 지향한다.
인텔이 최초로 발표했던 듀얼 코어 프로세서 펜티엄D의 경우 2개의 싱글 코어 프로세서 다이를 싱글 패키지로 묶은 것으로 사실상 2개의 프로세서 코어는 각기 고유의 캐쉬를 운용했으며 이 캐쉬 메모리는 상호 아무런 상관이 없었다. 그렇기 때문에 이 경우 각 코어의 캐쉬가 2MB이고 이것을 2x2MB=4MB라고 하는 것은 어불성설이나 다름 없으며 오히려 싱글 코어의 2MB 캐쉬보다 약간 더 나은 정도라고 보면 될 것이다.
이 경우 듀얼 코어에서 각 코어간의 캐쉬 정보가 공유되지 않으면 각 캐쉬는 같은 버스를 타고 각각 메모리에 접근해서 필요한 데이터를 가져 오려고 한다. 이 경우 FSB(Front Side Bus)는 당연히 트래픽이 늘어날 수 밖에 없다.
또한 캐쉬 효율성에서도 필요한 데이터가 다른 코어의 캐쉬에선 있는데 반대편 코어에서 없을 경우에는 같은 정보를 양쪽 캐쉬가 모두 보유하고 있어야 하는 낭비를 초래한다. 이는 비단 캐쉬 저장의 효율성을 떠나서도 어쨌든 양 회로가 모두 움직여야 한다는 기본적인 면에서 전력 소모량이 높을 수 밖에 없는 것이다.
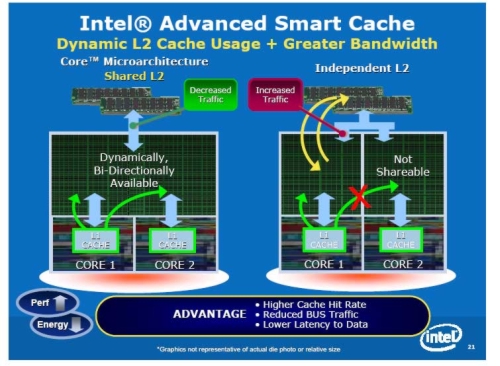
인텔은 코어 듀오, 요나 프로세서에 최초로 양 코어가 하나의 L2 캐쉬를 공유하는 스마트 캐쉬를 도입한다. 양 코어는 하나의 대형 캐쉬를 공유해서 실질적으로 각 코어가 가용할 수 있는 캐쉬 용량도 커졌을 뿐만 아니라 캐쉬 데이터 중복의 낭비도 없애고 메모리 버스의 병목 현상도 줄였다. 인텔은 메모리 컨트롤러를 아직 프로세서 내부에 넣지 않아도 현재 FSB 구조가 충분하다고 보고 있는데, 아직까지는 메모리 버스가 성능을 가로막는 병목현상이 일어나는 곳이 아니라고 밝히고 있다. 즉 내장된 메모리 컨트롤러는 높은 대역폭을 제공하는 이점도 있지만 오히려 더 프로세서 내부의 캐쉬 알고리듬이 뛰어나면 병목 현상이 일어날 일이 없다고 주장했다.
코어 아키텍쳐에서는 이보다 개선된 "어드밴스드 스마트 캐쉬(Advanced Smart Cache)"를 도입했다. 이 것은 요나의 공유 캐쉬와 기본적으로 같지만 전력 관리 부분이 더 개선되었고 데이터를 필요 이전에 가져오기 위한 프리페치(Pre-Fetch) 알고리듬도 개선되었으며 데이터공유 효율도 높아졌다고 인텔은 밝혔다.
안에서 새는 바가지부터 막자
코어 아키텍쳐가 모바일 프로세서인 요나에서 많은 부분을 승계했다는 것은 곧 전력 관리 기술도 아예 아키텍쳐 개발 초기부터 염두에 두고 개발되었다는 것과 일맥상통한다.
일반적으로 인텔의 전력 관리 기술은 프로세서에 부하가 적을 시에 클럭을 낮춰 전력 소모량을 줄이는 스피드스텝과 같은 프로세서 전체를 보는 거시적인 관점에서 기술로 시작했지만 코어 아키텍쳐에서는 전력 관리 기능이 이에서 미시적인 관점으로 더 확대하고 파고 들어 프로세서를 구성하는 유닛 하나하나에도 전력 관리 기술을 적용시켰다. 코어 아키텍쳐가 완전히 백지에서부터 다시 설계되었다는 것은 아마도 전력 관리 기술 부분에 있어 회로 하나하나에도 세심히 신경을 썼다는 의미로 보아도 좋을 것이다.
코어 아키텍쳐에는 다이상에 디지털 온도 센서를 구비하고 있으며 이 센서는 물론 과도한 전력 소모와 발열을 감지하고 해당 부분의 동작 여부를 판단하는 잣대로 사용하도록 되어 있다. 이것에서 한가지 흥미로운 것은 만약 발열에 있어 여유가 있으면 오히려 역으로 프로세서의 클럭을 끌어올린다는 것. 쉽게 이야기하면 자동 오버클럭이라는 이야기인데, 물론 이것은 아직 인텔이 정식 확인한 바는 아니며 프로세서 업계에서 도는 이야기정도에 불과하다.
코어 아키텍쳐의 듀얼 코어 프로세서에서 각 코어는 각각 독립적으로 전력 관리 기능을 수행한다. 즉 하나의 코어만이 필요한 작업에서는 나머지 하나 코어의 전력 소모량을 떨어뜨리는 것. 여기서 끝나지 않고 인텔은 코어 내부의 대부분의 버스에도 전력 소모 통제를 위한 일종의 게이트를 설치해 놓았다. 즉 특정 유닛으로 통하는 버스가 일정 시간 동안 트래픽이 없거나 낮을 경우에는 이 버스를 슬립 모드로 동작시킨다. 일례로 128비트 연산이 가능한 부동 소수 연산 유닛에서 만약 대부분의 연산데이터가 64비트라면 이 버스의 절반을 꺼버리는 것이다. 인텔이 이번 프로세서 아키텍쳐 개발시 얼마나 전력 관리 소모량에 신경을 썼나 엿볼 수 있는 부분이며 동시에 이전 프로세서가 많은 두통을 인텔에게 주었다는 것을 반증하는 것이기도 하다.
10.5년 농사를 준비한다. 코어 아키텍쳐
인텔은 7월 23일 정식으로 컨로 프로세서를 발표하고 시장 공략에 나설 예정이다. 아울러 이를 지원하기 위한 965 칩셋도 발표한 상태인데, 이미 마더보드 업체들이 다수의 965 칩셋 마더보드 샘플을 내놓고 있는 것으로 보아 이미 준비는 완료된 상태로 보인다. 컨로의 예정 가격은 다음과 같다.
E6700: 2.66 GHz / FSB 1066/ 4 MB 공유 L2 캐쉬, 가격 530달러
E6600: 2.40 GHz / FSB 1066/ 4 MB 공유 L2 캐쉬, 가격 316달러
E6400: 2.13 GHz / FSB 1066/ 2 MB 공유 L2 캐쉬, 가격 224달러
E6300: 1.86 GHz / FSB 1066/ 2 MB 공유 L2 캐쉬, 가격 183달러
E4200: 1.60 GHz / FSB 800/ 2 MB 공유 L2 캐쉬
Extreme Edition X6800 : 2.93GHz/ FSB 1066/ 4MB 공유 L2 캐쉬, 가격 999달러
인텔은 지난 인텔 개발자 포럼 이후부터 비공개를 조건으로 주요 리뷰어와 기자들을 불러 컨로를 시연해 보인 바 있다. 이 자리에는 2.66GHz의 컨로 시스템을 경쟁 업체인 AMD의 애슬론FX-60(2.8GHz로 오버클럭)과 직접 비교하도록 한 바 있는데, 그 성능은 이미 웹에서 다수 공개된 성능과 크게 다르지 않다. 물론 현재 대부분의 테스트 성능 측정을 위한 프로그램들, 일례로 벤치마크 프로그램이나 게임들,이 거의 싱글 쓰레드 애플리케이션임에도 불구하고 컨로는 인상적인 성능을 보여주고 있다. 코어는 멀티 코어를 지향한 아키텍쳐인만큼 인텔은 현재 사용되는 윈도우 XP가 이미 멀티 쓰레드를 지원하는 운영체제이기 때문에 그 혜택을 바로 컨로에서 얻을 수 있고, 앞으로 개발자들이 점점 더 멀티 쓰레드 애플리케이션을 개발할 경우 가면 갈수록 힘을 더 받을 수 있을 것으로 기대한다고 밝히고 있다.
그렇다면 하이퍼쓰레딩은 왜 빠졌을까? 인텔이 하이퍼쓰레딩의 펜티엄4가 최고 40%의 성능 향상을 낼 수 있다며 홍보하던 것과 달리 이번 컨로에서 하이퍼쓰레딩이 빠진 이유에 대한 인텔 엔지니어의 답변은 “가상 쓰레딩은 실제 물리적으로 2개의 쓰레드가 동작하는 것보다 우월하지 않기 때문”이라는 약간은 싱거운 답변을 들어야 만 했다.
그러나 업계에서는 하이퍼쓰레딩을 코어 아키텍쳐에 넣지 않은 이유는 바로 1개의 통합 아키텍쳐를 지향했기 때문이라는 설이 더 유력하다. 인텔은 코어 아키텍쳐로 데스크탑(코어 2듀오, 컨로), 서버(우드 크레스트), 모바일(메롬)의 모든 프로세서 라인업을 통일했다. 그러나 모바일 환경(노트북)에서 하이퍼쓰레딩은 사실상 사용 빈도를 볼때 서버 만큼의 혜택이 높지 않은 대신 전력 소모량은 증가하기 때문에 이를 빼버린 것으로 추정된다.
마지막으로 결론짓자면 현존하는 x86 마이크로프로세서 중 가장 비순차적 실행의 적용 점위가 넓고 에너지 효율도 높을뿐더러 싱글/멀티쓰레드 애플리케이션에서 모두 인상적인 성능을 낼 수 있는 기본기를 탄탄히 갖추고 있다고 평할 수 있겠다. 한 세대에서 다른 세대로 바뀌는 전이시기의 첫 제품은 사실 그다지 좋은 평을 듣지 못하는 것이 최첨단 정보기기의 되풀이되는 전통이다. 펜티엄 2에서 III로 넘어갈 때, 그리고 III에서 4로 넘어갈 때마다 인텔은 초기 성장통을 단단히 앓아야만 했다. 하지만 이번 코어 2 듀오 만큼은 내일 모레 장가가도 될 청년처럼 느껴진다.